우선순위 큐
일반적인 큐(Queue)는 First-In-First-Out(FIFO) 구조로, 먼저 들어온 데이터가 먼저 나가게 된다. 우선순위 큐는 일반적인 큐와는 다르게, 각 데이터에 우선순위가 존재하여 Pop 연산을 수행할 때 우선순위가 가장 높은 원소가 (or 우선순위가 가장 낮은 원소가) 나오는 큐이다.
우선순위 큐와 Linked List
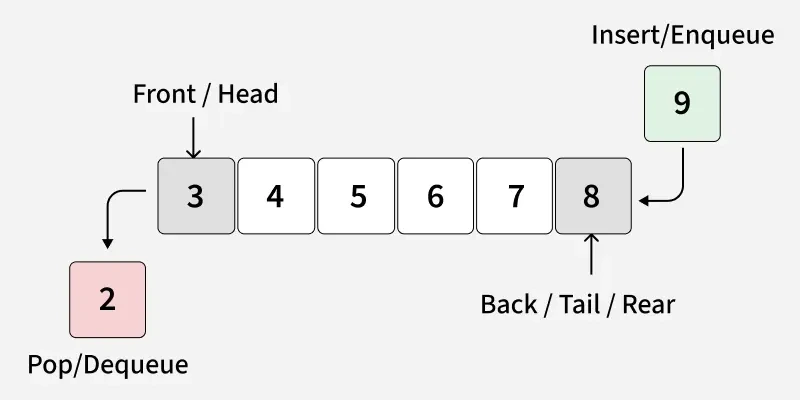
우선순위 큐는 일반적인 큐와 같이 Linked List를 이용해서 구현할 수 있다. 이렇게 구현하게 된다면 데이터 추가에 드는 시간복잡도는, Linked List의 Rear에 데이터를 추가하는 시간이므로 $O(1)$이 된다. 그러나, 우선순위 큐에서 값을 제거하는 연산은, 최대값 or 최소값을 찾아야하므로 Linked List 내부의 모든 데이터를 확인해야만 가능하다. 즉, $O(N)$의 시간복잡도를 가지게 된다. 마찬가지로 우선순위가 제일 높거나 낮은 원소를 확인하는 데에도 똑같이 $O(N)$의 시간복잡도를 갖게 된다.
힙 (Heap)
힙은 완전이진트리(Complete Binary Tree)의 일종으로 아래와 같은 특징을 가지고 있다.
- 각 노드의 자식은 최대 2개이며, 트리의 마지막 레벨에는 왼쪽부터 차례대로 노드가 채워져 있다. (=완전이진트리)
- 트리 내의 어떤 노드에서도, 부모 노드와 자식 노드 간에는 일정한 대소관계가 성립한다.
- 힙 내에 중복된 데이터가 허용된다.
힙의 종류에는 최대 힙, 최소 힙 두 가지가 있다.
- 최대 힙 (Max Heap): 부모 노드의 값이 자식 노드의 값보다 항상 크거나 같은 힙
- 최소 힙 (Min Heap): 부모 노드의 값이 자식 노드의 값보다 항상 작거나 같은 힙
위와 같은 성질에 의해서, 최대 힙의 Root에는 해당 힙 내부의 최댓값이, 최소 힙의 Root에는 해당 힙 내부의 최소값이 존재하게 된다.
이때, 우선순위 큐를 Linked List로 구현했을 때의 문제점을 해결하기 위해서 힙을 이용해서 우선순위 큐를 구현할 수 있다.
구현
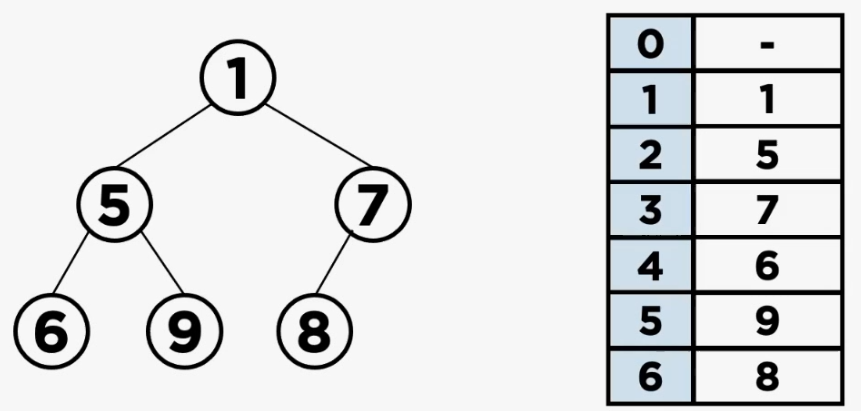
힙은 일반적으로 배열을 이용해서 구현할 수 있다. 힙은 완전이진트리이므로, Root 노드의 인덱스틑 1이라고 했을 때, 특정 위치 $x$의 왼쪽 자식 노드는 $2x$, 오른쪽 자식 노드는 $2x+1$의 인덱스를 갖게 된다. 또한, 부모 노드는 $\lfloor \frac{x}{2} \rfloor$가 된다.
이진 탐색 트리를 배열로 구현하지 못하는 이유?
힙은 완전이진트리이므로, 값이 배열의 순서대로 채워진다. 그러나, 이진 탐색 트리는 불균형이 발생할 수 있기 때문에, 배열 중간에 계속해서 빈 값이 발생하게 된다. 따라서 최악의 경우 공간이 $O(2^N)$만큼 필요하므로 문제가 된다.
또한, 이진 탐색 트리의 균형을 맞추는 과정에서 Rotation이 발생하게 되는데, 이때 값들의 인덱스를 모두 변경해야 하는 문제가 발생할 수 있다. 따라서 전체 서브트리 데이터의 값을 변경하는 시간이 소요되므로 배열로 구현하는 것이 손해이다.
확인 (Find)
최대 힙 및 최소 힙에서 다음에 출력될 값은 단순히 Root 노드의 값을 확인하면 된다. 따라서 시간복잡도는 $O(1)$이다.
삽입 (Insert)
최대 힙의 경우에서 새로운 데이터가 삽입되는 방식은 다음과 같다.
- 힙의 제일 마지막 노드 다음으로 새로운 데이터를 값으로 하는 노드를 추가한다.
- 추가한 노드의 부모 노드와 대소 비교를 하여, 부모 노드가 더 작다면 값을 교환한다.
- 부모 노드의 값이 작지 않거나, 더 이상 교환할 수 없을 때까지 2번을 반복한다.
최소 힙은 대소 관계를 바꾸면 똑같이 작동한다.
위와 같은 경우에서는, 최대로 일어날 수 있는 교환의 횟수가 힙의 높이만큼이 된다. 이때, 힙은 완전이진트리라서 불균형하지 않기 때문에, 높이는 $\log N$이 되므로 시간복잡도 또한 $O(\log N)$이 된다.
삭제 (Remove)
최대 힙, 최소 힙 모두 Root 노드가 다음에 삭제될 값이므로 해당 노드를 삭제해야 한다. 그러나 삭제된 이후에도 힙의 성질이 유지되어야 하므로, 다음과 같은 방법으로 힙을 복구한다.
- 제거할 Root 노드와 힙의 제일 마지막 노드를 교환한다.
- 이동된 Root 노드를 제거한다.
- 가져온 제일 마지막이었던 노드를 자식 노드와 비교해 가면서, 힙의 성질에 맞도록 값을 교환한다.
- 최대 힙의 경우, 자식 노드 중 최대값과 비교한다.
- 최소 힙의 경우, 자식 노드 중 최소값과 비교한다.
이 경우도 마찬가지로, 최대 교환 횟수가 힙의 높이만큼이다. 따라서, 삭제 연산도 시간복잡도는 $O(\log N)$이 된다.
따라서, Linked List와 힙으로 구현한 우선순위 큐의 시간복잡도를 비교해보면 아래와 같다.
| Linked List | Heap | |
| Find | $O(N)$ | $O(1)$ |
| Insert | $O(1)$ | $O(\log N)$ |
| Remove | $O(N)$ | $O(\log N)$ |
Python에서의 힙
Python에서는 heapq 패키지를 이용해서 힙을 이용한 우선순위 큐를 이용할 수 있다.
heapq.heappush(heap, item)→heap에item을 삽입한다.heapq.heappop(heap)→heap에서 값을 삭제한다.heapq.heapify(x)→리스트x를 힙으로 변환한다.
이때, heapq 패키지는 최소 힙만을 지원한다. 따라서, 최대 힙으로 이용하기 위해서는 값에 “-”를 붙여 힙에 넣는 방식을 사용할 수 있다. ($y=-x$에서 $x$가 커질수록 $y$는 작아지는 것을 이용할 수 있다!)
특히, 위와 같이 구성된 heap 객체의 맨 처음 인덱스에는 항상 우선순위 최소인 값이 존재하게 된다.
References
'Algorithm > 개념 정리' 카테고리의 다른 글
| 소수 판별 알고리즘 (0) | 2026.05.01 |
|---|---|
| 이진 탐색 트리 (Binary Search Tree) (1) | 2026.04.28 |
| 투 포인터 (Two Pointers) (1) | 2026.04.22 |
| 이진 탐색 (Binary Search) (0) | 2026.04.22 |
| 그리디 알고리즘 (Greedy Algorithm) (0) | 2026.04.22 |